

Building a Regression Model to Predict Sales Revenue using Sci-Kit Learn
In this guide, we will learn how to build a multiple linear regression model with Sci-kit learn. Unlike the Simple Linear Regression model that uses a single feature to make predictions, the Multiple Linear Regression model uses more than one feature to make predictions. It shows the relationship between multiple independent variables and a dependent variable. You can read the guide on how to build a Simple Linear Regression model with Sci-kit Learn by clicking here.
Prerequisite
- A PC with Jupyter Notebook IDE
- Advertising dataset from Kaggle
- Basic Knowledge of Multiple Linear Regression
Multiple linear regression
The formula of multiple linear regression is:
y = θ0 + θ1 x1 + θ2 x2 + … + θn xn
where n represents the number of features in our dataset
For our dataset with 3 features, we will have the formula
Sales = θ0 + θ1 * TV + θ2 * radio + θ3 * newspaper
IMPORTING DATASET
Let us import the libraries we will be using.
# importing libraries
import numpy as np
import pandas as pd
import seaborn as sns
from scipy.stats import skew
%matplotlib inline
import matplotlib.pyplot as plt
# using ggplot style
plt.style.use("ggplot")
# setting width and height of plot
plt.rcParams['figure.figsize'] = (12, 8)We will now load our data.
# Load the Data
advert = pd.read_csv('Advertising.csv')
advert.head()
advert.info()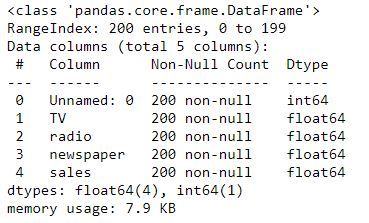
We have 5 columns in our dataset. We will remove the ‘Unnamed: 0’ since we don’t need the index column.
# Removing the index column
advert.drop(['Unnamed: 0'], axis=1, inplace=True)Exploratory Data Analysis
We have 3 features and a target variable in our dataset. Let’s explore the relationship between the features and the target variable.
# Checking relationship between Features and Response
sns.pairplot(advert, x_vars=['TV', 'radio', 'newspaper'],
y_vars='sales', height=7, aspect=0.7)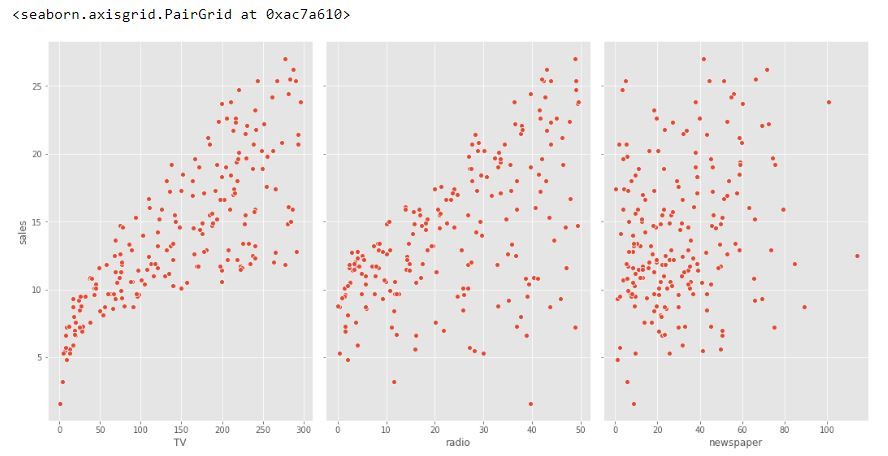
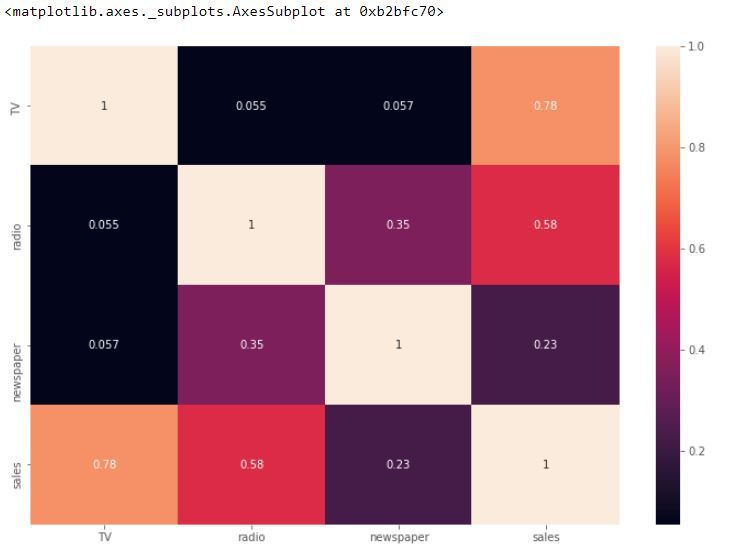
# Viewing the heatmap
sns.heatmap(advert.corr(), annot=True)Using the seaborn heatmap, we can see the correlation of each column to the other column. The TV column has the highest correlation to the Sales column, which is 0.78.
Feature Selection Using R2
Feature Selection involves choosing features that will help us build a good model. In most cases, not all the features in our dataset will help us get a good model. We have to remove irrelevant features that can reduce the performance of our model. In this guide, we will be using R squared.
R squared (R2) is a goodness of fit measure for linear regression models. It measures the strength of the relationship between your model and the dependent variable. It ranges from 0 – 1. The larger the R2, the better the regression model fits the observations. You can read more about R2 from here.
We will import the r2 score function from the metrics module of the sklearn library. We will import the LinearRegression() class from the linear_model module of the sklearn library.
We will also extract our features and the target variable.
# Checking R_squared between 'TV', 'newspaper'
from sklearn.metrics import r2_score
from sklearn.linear_model import LinearRegression
X = advert[['TV', 'radio', 'newspaper']]
y = advert.salesWe will now fit the linear regression model to our dataset. We are using just the TV and newspaper features and we are training on and evaluating the entire dataset. Our goal here is to see the R2 score.
# We are training and evaluating on the entire dataset
lm1 = LinearRegression().fit(X[['TV', 'newspaper']], y)
lm1_preds = lm1.predict(X[['TV', 'newspaper']])
print("R^2: ", r2_score(y, lm1_preds))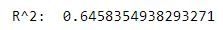
Our R2 score is approximately 0.6458. Now we will use just the TV and radio features this time and see what our R2 score will be.
# Checking R_squared between 'TV', 'radio'
lm2 = LinearRegression().fit(X[['TV', 'radio']], y)
lm2_preds = lm2.predict(X[['TV', 'radio']])
print("R^2: ", r2_score(y, lm2_preds))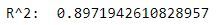
We get an R2 score of 0.8972, which is higher than what we had when using the TV and newspaper features.
# Checking R_squared between 'TV', 'radio', 'newspaper'
lm3 = LinearRegression().fit(X[['TV', 'radio', 'newspaper']], y)
lm3_preds = lm3.predict(X[['TV', 'radio', 'newspaper']])
print("R^2: ", r2_score(y, lm3_preds))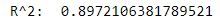
So by adding the newspaper feature, our R2 score did not improve by much. We can drop the newspaper feature from the model. Keeping the newspaper feature will likely lead to poor results on the test set.
Evaluating the Model
We will split our dataset into the training and test set, and we will use the Root Mean Squared Error (RMSE) to evaluate our model. We will see if the newspaper feature should be kept in the model. Let’s use all three features and see the RMSE and R2 on the test set.
# Model Evaluation using Train/Test and Metrics
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Using all three features
X = advert[['TV', 'radio', 'newspaper']]
y = advert.sales
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
lm4 = LinearRegression().fit(X_train, y_train)
lm4_preds = lm4.predict(X_test)
print("RMSE: ", np.sqrt(mean_squared_error(y_test, lm4_preds)))
print("R^2: ", r2_score(y_test, lm4_preds))
Our RMSE and R2 are approximately 1.4047 and 0.91562 respectively. Let’s use just the TV and radio features and see what our RMSE and R2 will be.
# Using just TV and radio features
X = advert[['TV', 'radio']]
y = advert.sales
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
lm5 = LinearRegression().fit(X_train, y_train)
lm5_preds = lm5.predict(X_test)
print("RMSE: ", np.sqrt(mean_squared_error(y_test, lm5_preds)))
print("R^2: ", r2_score(y_test, lm5_preds))
Our RMSE and R2 are approximately 1.3879 and 0.9176 respectively. Our RMSE has reduced and the R2 has improved. This shows that the lm5 model is better than the lm4 model. So without the newspaper feature, we get a better model. Now let’s try to see what our RMSE and R2 will be if we should use the TV and newspaper column.
# Using just TV and newspaper features
X = advert[['TV', 'newspaper']]
y = advert.sales
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
lm6 = LinearRegression().fit(X_train, y_train)
lm6_preds = lm6.predict(X_test)
print("RMSE: ", np.sqrt(mean_squared_error(y_test, lm6_preds)))
print("R^2: ", r2_score(y_test, lm6_preds))

So with just the TV and newspaper features, we get a really bad model with an RMSE of approximately 3.3520 which is high and the R2 score is low.
The best model so far is the lm5 model. It has the highest R2 score and the lowest RMSE. So we will use the lm5 model.
Conclusion
In this guide, we learned how to build a multiple linear regression model with sci-kit learn. We also learned how to do feature selection using R2. Feature Selection helps us to choose the features that will give us a good model. We used R2 to measure the strength of the relationship between our model and the dependent variable.
The Github repo is here.